Open Policy Agent
Introduction
Implementing guardrails and policy is one of the first steps to enabling self-service IaC deployments. Policies give administrators peace of mind that their end users are deploying in a safe and compliant way.
Scalr utilizes Open Policy Agent (OPA) to govern Terraform and OpenTofu deployments. OPA is policy-as-code that uses the rego language to evaluate Terraform input data against administrator defined rules. Any data in the Terraform JSON can be evaluated as part of the OPA checks. The evaluation returns a result, which is then interpreted by Scalr to determine what course of action to take. To be clear, OPA does not make any decisions regarding a policy, and it simply returns a result (true, false, some text) which Scalr then uses to make a decision.
The OPA code is treated similarly to your Terraform code in that it is stored in a VCS provider and managed through a GitOps model. Administrators create, manage, and open pull requests on the policies directly in VCS providers and trigger speculative runs to preview the impact of policy changes.
There are two main sections that the policies can evaluate, the tfplan and tfrun. The Terraform input data will be the output of the Terraform plan (tfplan in rego) and the run time (tfrun in rego) environment data, such as workspace details, usernames, run sources, etc. From this data, OPA can evaluate the attributes of all Terraform providers, resources, data, and anything mentioned in the plan.
Pre-Plan vs Post Plan Policy Checks
Scalr implements OPA checks in two different stages: pre-plan and/or post-plan. The pre-plan stage can only evaluate information available before the plan, such as the run source, who executed the run, VCS details, and more. The post-plan stage can evaluate everything included in the pre-plan as well as information included in the terraform plan JSON, specifically deployment details about the resources being created, changed, and deleted.
Pre-Plan
The pre-plan checks execute right before the Terraform plan stage. At this stage, Scalr has access to the tfrun data, which OPA can evaluate. The tfrun data contains information such as the run source, the user who executed the run, commit authors, workspace name, and anything else that is around how the run execution started:
tfrun
{
"tfrun": {
"workspace": {
"name": "workspace-a",
"description": null,
"auto_apply": true,
"working_directory": "",
"environment_type": "unmapped",
"tags": [],
"module": null,
"provider_configurations": [
{
"id": "pcfg-v0ohpfbns0lsj1234",
"name": "AWS-CS",
"provider": "aws"
},
{
"id": "pcfg-v0ohpf7kmpme12345",
"name": "scalr-admin",
"provider": "scalr"
}
]
}
},
"environment": {
"id": "env-tkaervoct5ou123",
"name": "Environment A"
},
"vcs": {
"repository_id": "rtfee/null_resource_module",
"path": "",
"branch": "main",
"commit": {
"sha": "83714928d9a5dec29268c40dcc31e472e521ceea",
"message": "Merge pull request #4 from user/dev\n\nUpdate main.tf",
"author": {
"name": "John",
"email": "[email protected]",
"username": "john123",
"teams": null
}
},
"pull_request": {
"author": "john123",
"merged_by": "john123"
}
},
"cost_estimate": null,
"source": "dashboard-workspace",
"message": "Merge pull request #4 from user/dev\n\nUpdate main.tf",
"is_destroy": false,
"is_dry": false,
"created_by": {
"name": null,
"email": "[email protected]",
"username": "[email protected]",
"origin_ip": "68.1760.100.0",
"user_agent": "go-tfe",
"teams": [
{
"id": "team-uc8rrb9qoudc123",
"name": "Module Team"
}
]
},
"shell_variables": [
{
"key": "SCALR_RUNNER_ROLE",
"value": "runner-account-access"
}
]
}Pre-plan checks improve the developer experience by stopping runs that violate policy early on in the pipeline rather than waiting for the plan to run. Any runs that error or are denied at this stage are not billed for.
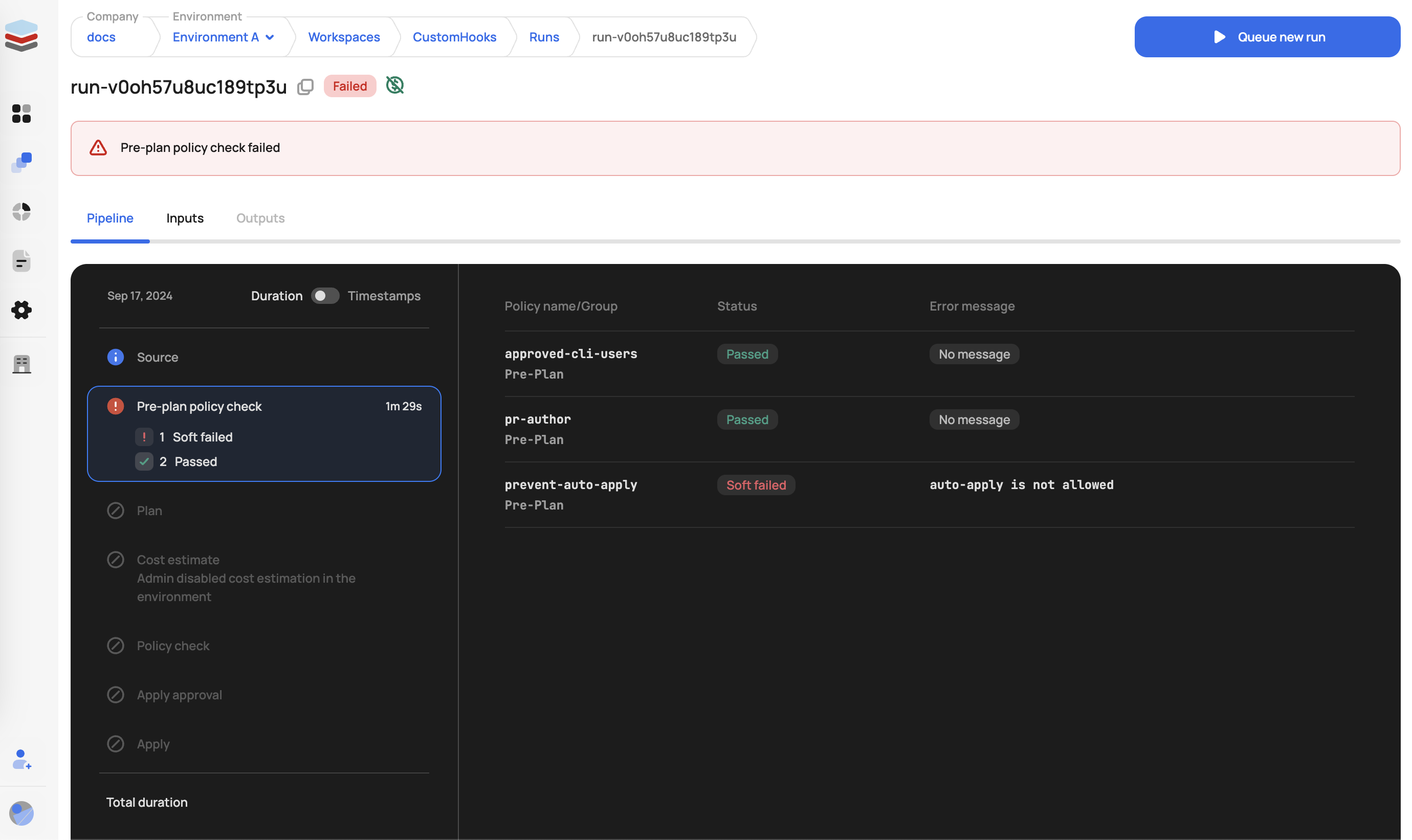
The following enforcement levels can be applied to pre-plan checks in the scalr-policy.hcl (see more on this below):
- Hard Mandatory - Causes the run to go into an errored state with an error message.
- Soft Mandatory - Causes the run to go into an errored state with an error message.
- Advisory - Provides a warning only, the run can continue.
You may be wondering why soft and hard policies end in the same result. At this time, the ability to have different results for soft and hard policies only applies to the post-plan policies.
Post-Plan
The post-plan checks execute right after the Terraform plan stage. At this stage, Scalr has access to the tfrun and tfplan data, which OPA can evaluate. The tfrun data contains information such as the run source, the user who executed the run, commit authors, workspace name, and anything else that is around how the run execution started (as seen above). The tfplan data is generated based on the Terraform plan output:
tfplan
"tfplan": {
"format_version": "1.2",
"terraform_version": "1.5.2",
"planned_values": {
"root_module": {
"resources": [
{
"address": "null_resource.example",
"mode": "managed",
"type": "null_resource",
"name": "example",
"provider_name": "registry.terraform.io/hashicorp/null",
"schema_version": 0,
"values": {
"id": "3177230123079022363",
"triggers": null
},
"sensitive_values": {}
},
{
"address": "null_resource.example2",
"mode": "managed",
"type": "null_resource",
"name": "example2",
"provider_name": "registry.terraform.io/hashicorp/null",
"schema_version": 0,
"values": {
"triggers": null
},
"sensitive_values": {}
}
]
}
},
"resource_changes": [
{
"address": "null_resource.example",
"mode": "managed",
"type": "null_resource",
"name": "example",
"provider_name": "registry.terraform.io/hashicorp/null",
"change": {
"actions": [
"no-op"
],
"before": {
"id": "3177230123079022363",
"triggers": null
},
"after": {
"id": "3177230123079022363",
"triggers": null
},
"after_unknown": {},
"before_sensitive": {},
"after_sensitive": {}
}
},
{
"address": "null_resource.example2",
"mode": "managed",
"type": "null_resource",
"name": "example2",
"provider_name": "registry.terraform.io/hashicorp/null",
"change": {
"actions": [
"create"
],
"before": null,
"after": {
"triggers": null
},
"after_unknown": {
"id": true
},
"before_sensitive": false,
"after_sensitive": {}
}
}
],
"prior_state": {
"format_version": "1.0",
"terraform_version": "1.5.2",
"values": {
"root_module": {
"resources": [
{
"address": "null_resource.example",
"mode": "managed",
"type": "null_resource",
"name": "example",
"provider_name": "registry.terraform.io/hashicorp/null",
"schema_version": 0,
"values": {
"id": "3177230123079022363",
"triggers": null
},
"sensitive_values": {}
}
]
}
}
},
"configuration": {
"provider_config": {
"null": {
"name": "null",
"full_name": "registry.terraform.io/hashicorp/null"
}
},
"root_module": {
"resources": [
{
"address": "null_resource.example",
"mode": "managed",
"type": "null_resource",
"name": "example",
"provider_config_key": "null",
"provisioners": [
{
"type": "local-exec",
"expressions": {
"command": {
"constant_value": "echo 'Congrats on your first run! Woohoo!!!!'"
}
}
}
],
"schema_version": 0
},
{
"address": "null_resource.example2",
"mode": "managed",
"type": "null_resource",
"name": "example2",
"provider_config_key": "null",
"provisioners": [
{
"type": "local-exec",
"expressions": {
"command": {
"constant_value": "echo 'Congrats on your first run! Woohoo!!!!123'"
}
}
}
],
"schema_version": 0
}
]
}
},
"timestamp": "2024-09-17T17:27:39Z"
}Post-plan checks help with security standards regarding the creation and deployment of provider resources. For example, they can be used to prevent users from deploying public S3 buckets or restrict which Terraform providers can be used.
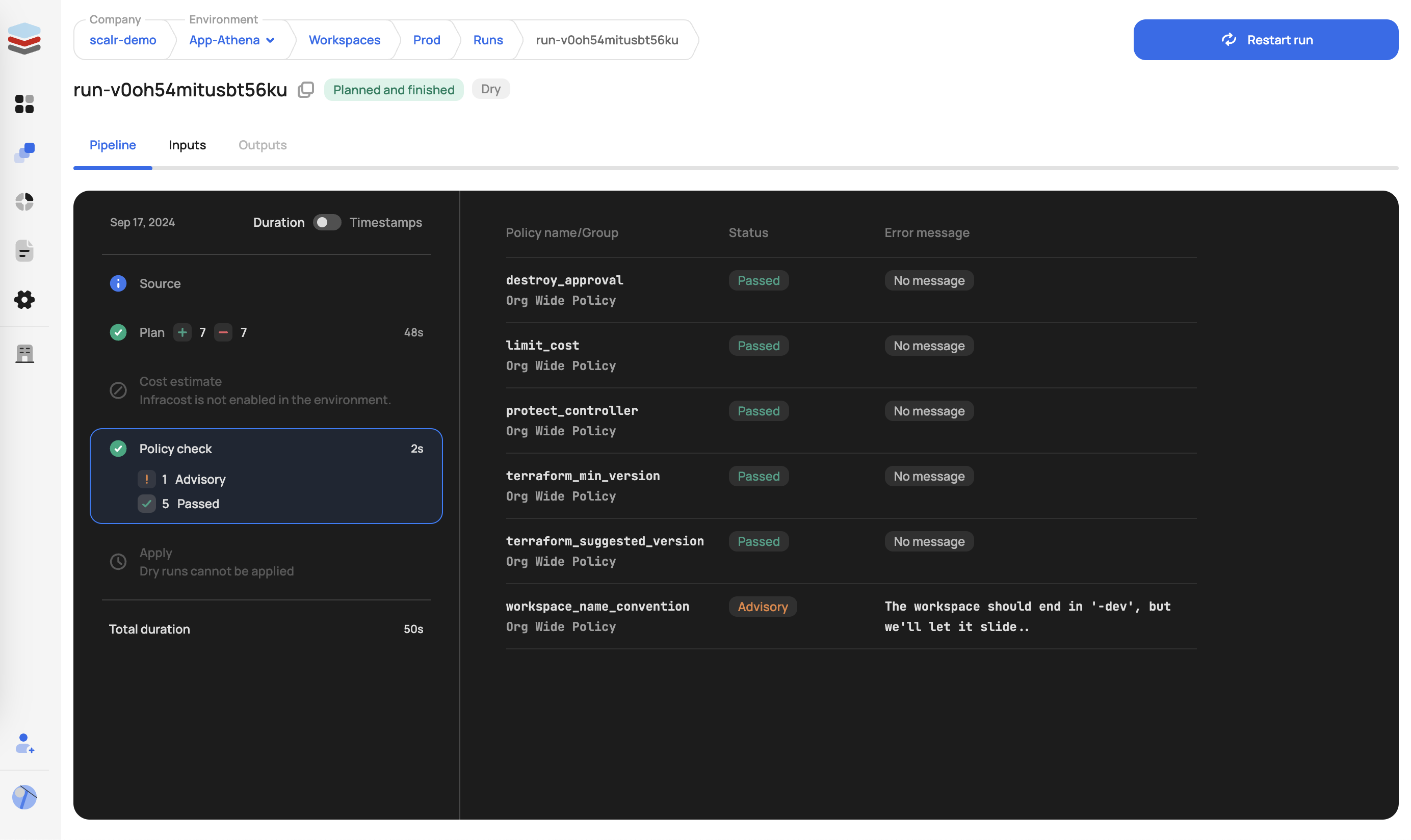
The following enforcement levels can be applied to post-plan checks:
- Hard Mandatory - Causes the run to go into an errored state with an error message.
- Soft Mandatory - Causes the run to go into an approval state, users with the permission
policy-checks:overridecan approve or deny the run. In plan-only runs, soft-mandatory policies behave like hard mandatory and will fail the PR. - Advisory - Provides a warning only; the run will continue.
Creating an OPA Policy
When writing an OPA policy to be used in Scalr, the package must be namedterraform as seen in the example below.
Scalr requires that the OPA evaluation returns an array of strings named deny. Scalr will interpret the presence of any values in the array as a policy failure. Thus, in policies used with Scalr, a rule named deny must always perform the evaluation. Here is a very simple example that checks the cost of the resources in a Terraform run using the cost estimation data:
package terraform
import input.tfrun as tfrun
deny[reason] {
cost_delta = tfrun.cost_estimate.delta_monthly_cost
cost_delta > 10
reason := sprintf("Plan is too expensive: $%.2f, while up to $10 is allowed", [cost_delta])
}An evaluation that detects the cost to be higher than $10 would return a result like this:
{
"deny": [
"Plan is too expensive: $12.00, while up to $10 is allowed"
]
}All deny rules are independent and if at least one rule fails - it will fail the entire group and then depending on the enforcement level will mark it either advisory or fail the run.
The import function will either be tfrun or tfplan or both, depending on the data you want to evaluate and if it is a pre or post plan policy:
import input.tfrun as tfrun
import input.tfplan as tfplan
Creating Policy Groups
Once OPA policies are created, you then want to create a policy group. A policy group is the collection of one or more OPA policies stored in a repository with a scalr-policy.hcl file declaring if the policies are enabled and what the enforcement level is. One or more policy groups can be attached to each environment, and it is normal to have a common policy group shared across all environments as well as environment-specific policy groups to ease overhead. Common shared policy groups could include restricting network access, preventing public S3 buckets, allowing specific Terraform modules, and much more. The following example helps with the basics, if you have commonly shared OPA code that you want to reuse, please see the functions section below.
Create policy rego files in a VCS repo:
 Note: The above repo can be found here.
Note: The above repo can be found here.
Add a scalr-policy.hcl file to set the enforcement levels and if the policy is enabled or not for each policy file in the repo, as shown in this example. If a the name of the rego file is not included in the scalr-policy.hcl, then it will be ignored. Note the version is required:
version = "v1"
#policy "terraform_version_check" {
# enabled = true
# enforcement_level = "soft-mandatory"
#}
policy "terraform_min_version" {
enabled = true
enforcement_level = "hard-mandatory"
}
policy "terraform_suggested_version" {
enabled = true
enforcement_level = "soft-mandatory"
}
policy "limit_modules" {
enabled = false
enforcement_level = "soft-mandatory"
}
policy "workspace_name_convention" {
enabled = true
enforcement_level = "advisory"
}
policy "limit_cost" {
enabled = true
enforcement_level = "soft-mandatory"
}
policy "protect_controller" {
enabled = true
enforcement_level = "soft-mandatory"
}
policy "destroy_approval" {
enabled = true
enforcement_level = "soft-mandatory"
}After the files are created in your repo, go into Scalr, the run policy engine, and create the policy group. To use policy groups, it is necessary to create a VCS providerin Scalr if this has not already been done. Go to integrations at the account scope, then OPA, and create a policy group:
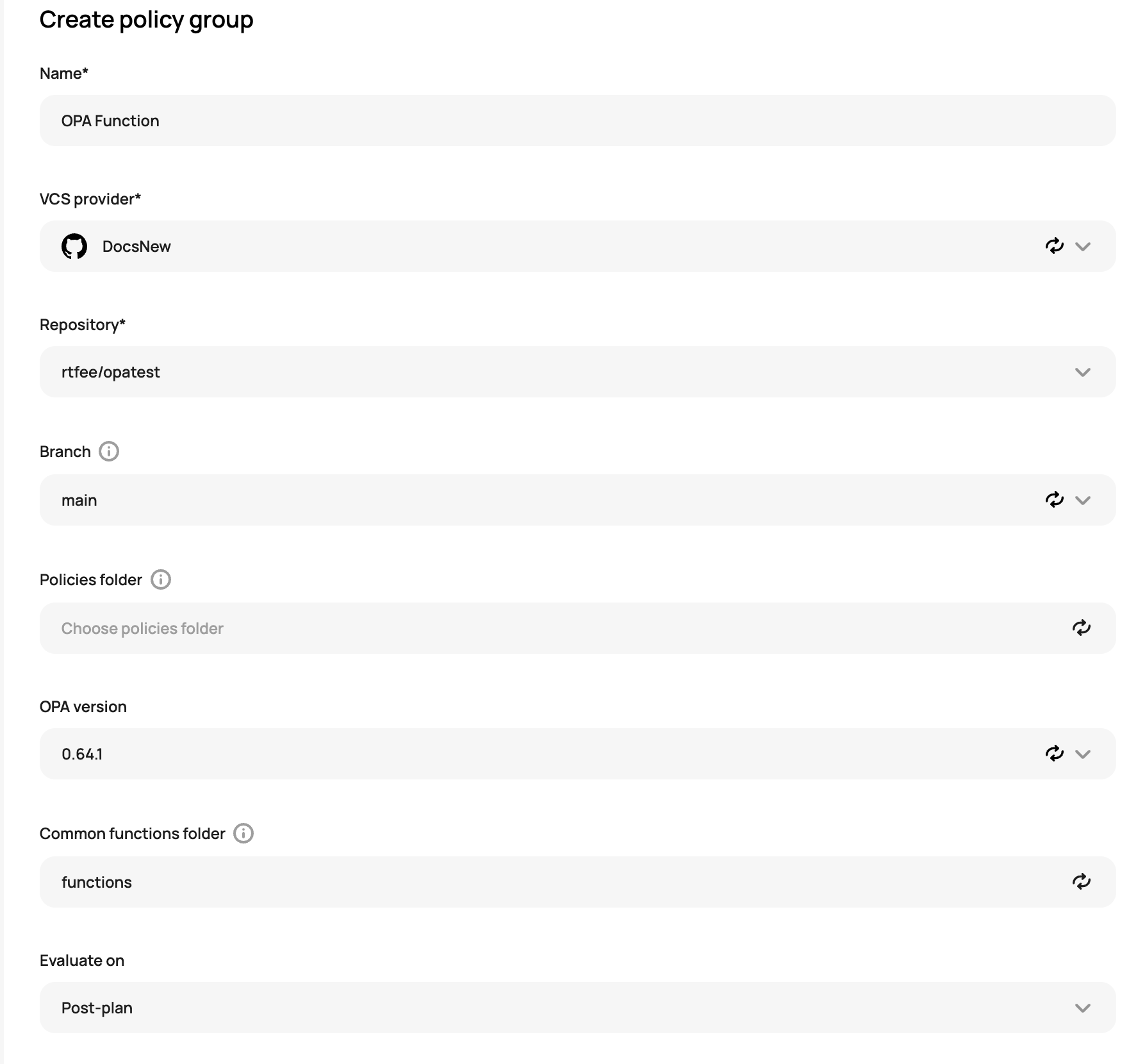
Select if the policy should run as a pre-plan or post-plan checks. Save the policy and then enforce it on environments by clicking on "Enforce run policy group":
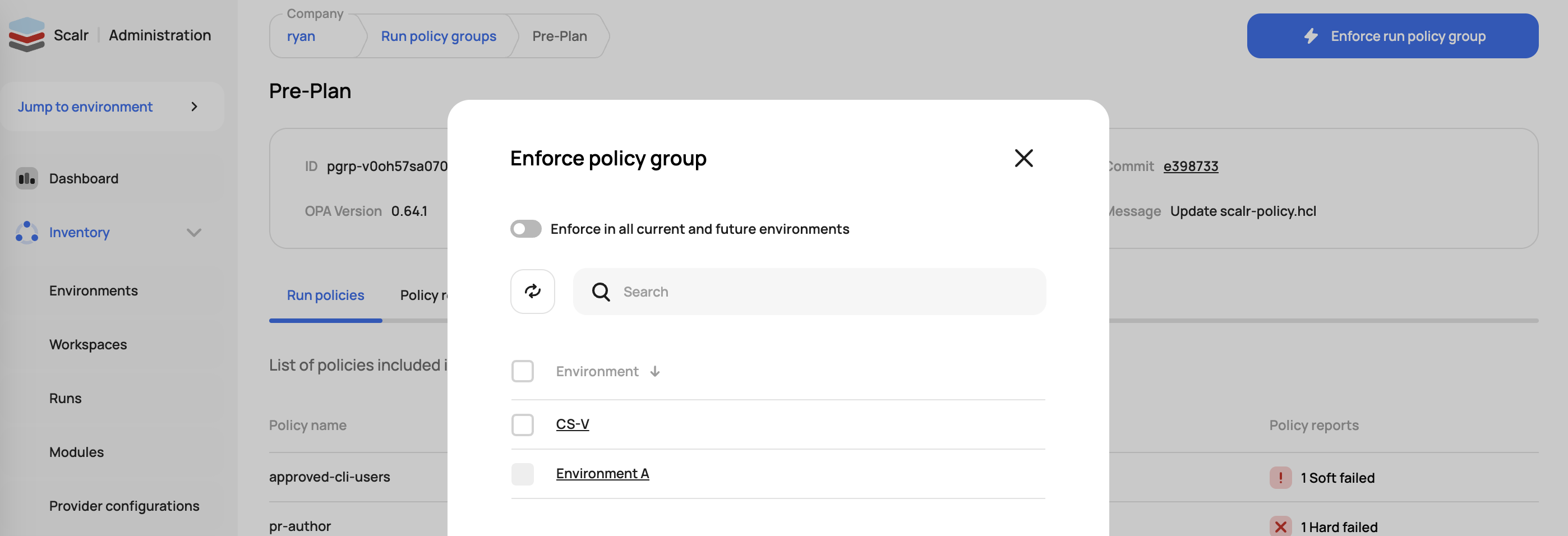
Policy reports will appear within a few seconds (maybe longer depending on the amount of workspaces) once the policy is enforced. The policies will automatically be applied to all workspaces in the environments and the results can be viewed within a run:
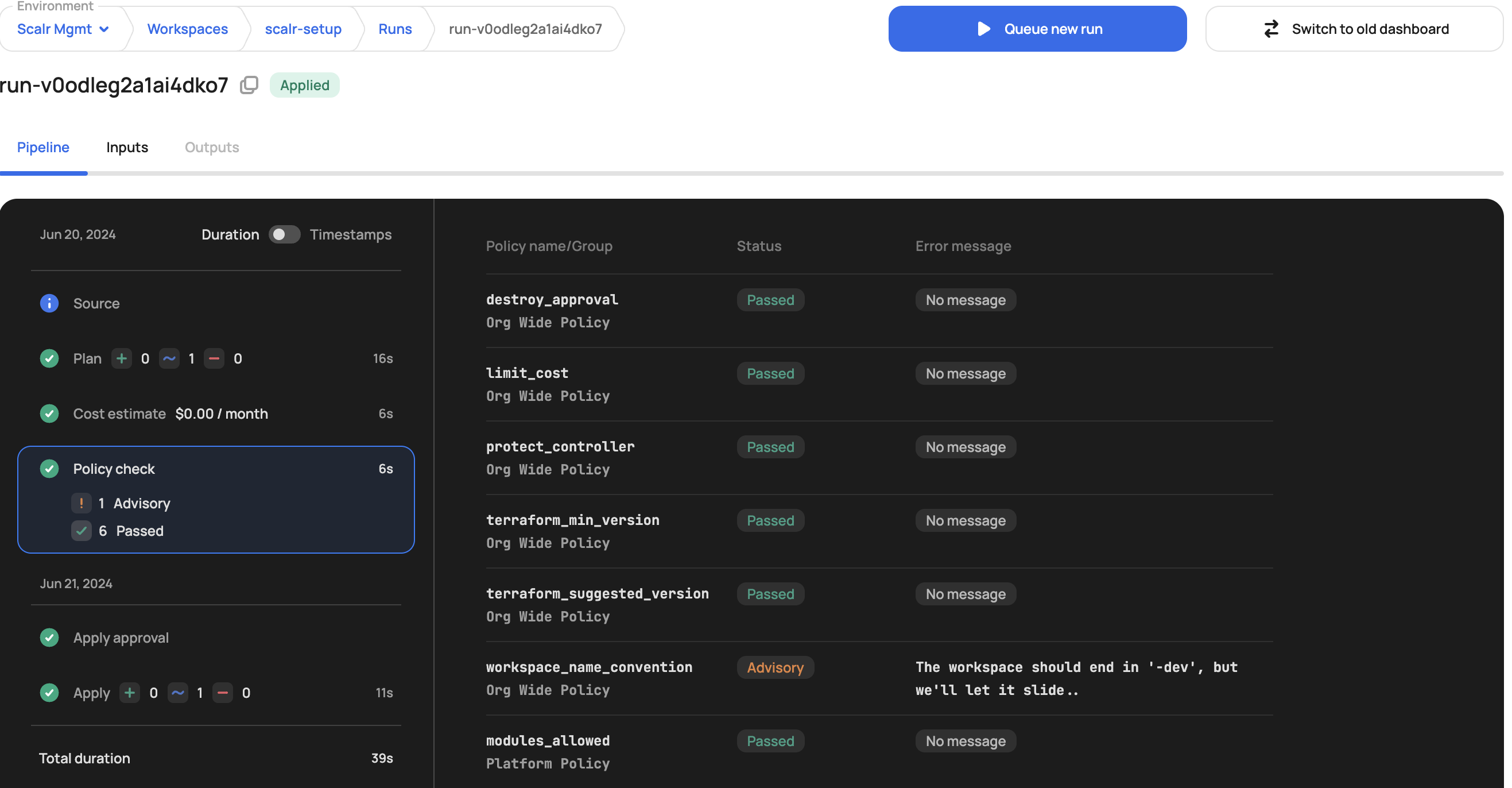
Functions
Scalr supports OPA functions, allowing OPA admins to specify a path for common Rego functions. This enables Scalr to import shared functions before each policy evaluation, reducing code duplication and simplifying OPA policy management. To use functions, there are three main steps:
- Create the function
- Import the function into the main OPA rego file
- Set the path to the function in Scalr
Function:
Note that the file name in this case is utils.rego(Designed for OPA versions 1.0 and higher)
package utils
array_contains(arr, elem) if {
arr[_] = elem
}
get_basename(path) = basename if {
arr := split(path, "/")
basename := arr[count(arr)-1]
}Main Rego File:
Note that the function is imported with import data.utils as it references the function file name. (Designed for OPA versions 1.0 and higher)
#Prevent specified providers from being used
package terraform
import input.tfplan as tfplan
import data.utils
# Blacklisted Terraform providers
not_allowed_provider := [
"null"
]
deny contains reason if {
resource := tfplan.resource_changes[_]
action := resource.change.actions[count(resource.change.actions) - 1]
utils.array_contains(["create", "update"], action) # allow destroy action
provider_name := utils.get_basename(resource.provider_name)
utils.array_contains(not_allowed_provider, provider_name)
reason := sprintf(
"%s: provider type %q is not allowed!",
[resource.address, provider_name]
)
}The function is pulled into the policy check by Scalr when the function folder is defined:
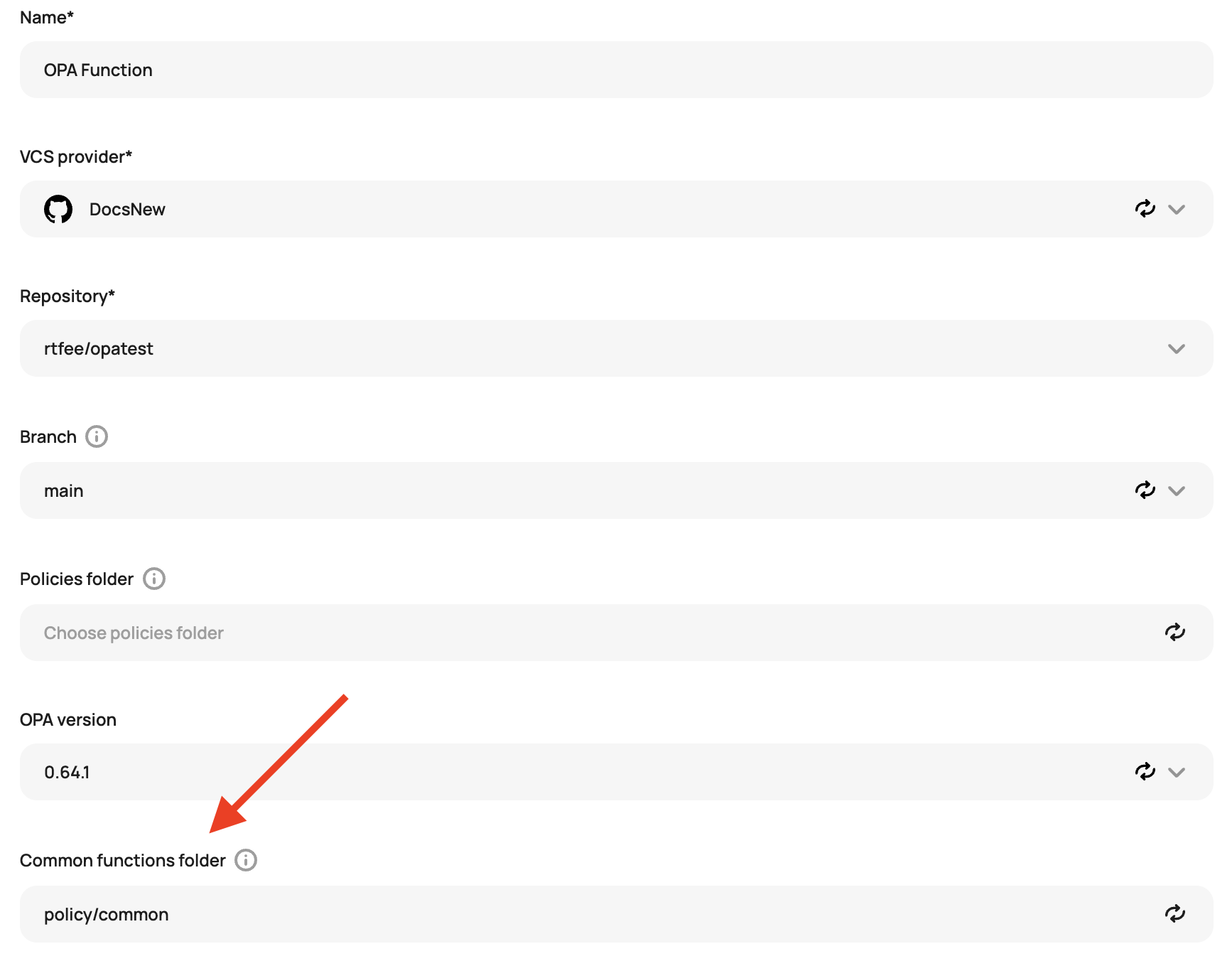
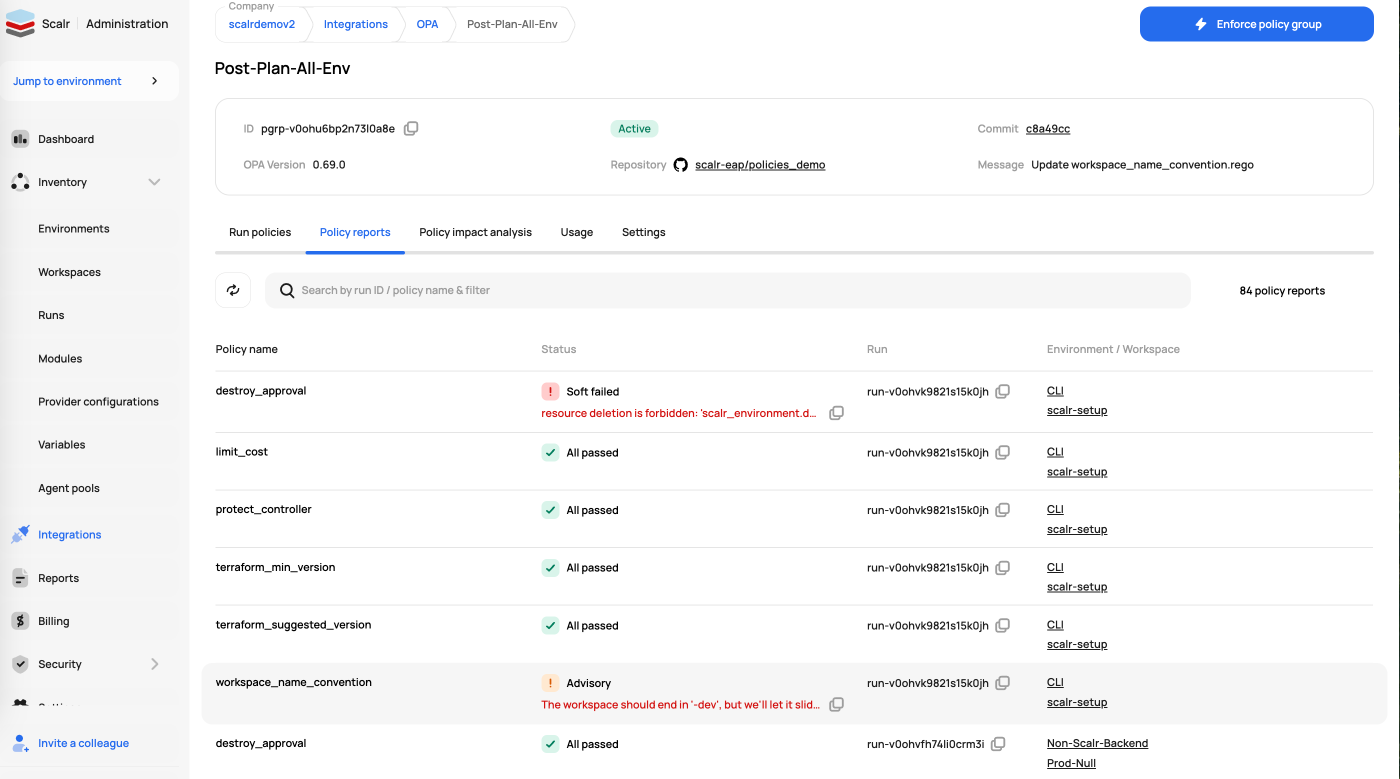
Policy Reports
Once a policy group is created and assigned to environments, Scalr will automatically start populating the reports for that policy group. The report will retroactively run on all workspace the policy group is linked to and update once new run are executed within the workspace. The policy group reports gives you a single view of the current results of policies across all environments and workspaces.
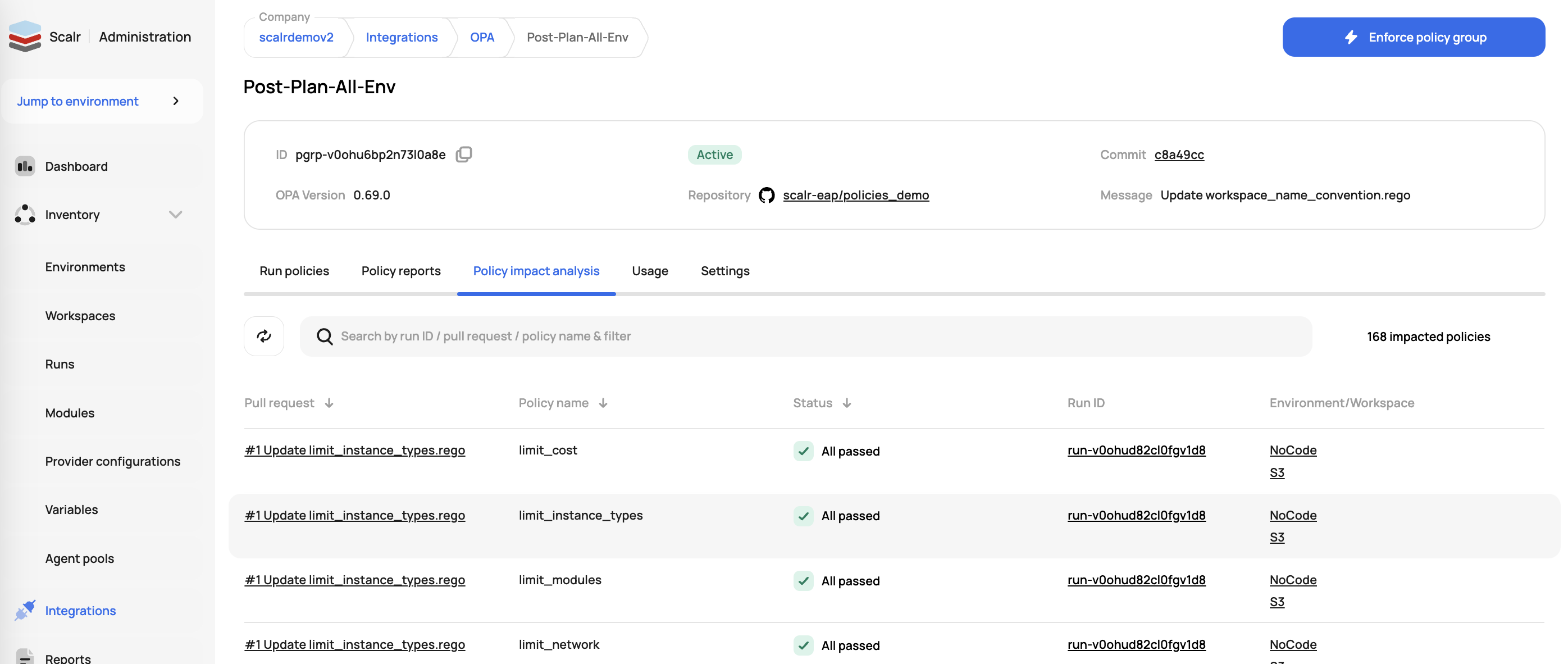
Policy Impact Analysis
Scalr provides a preview of future policy changes based on pull requests against the repository linked to the policy group. Similar to a Terraform dry run, but for OPA! This report gives administrators the piece of mind to know if they made an error updating the policy or if there are workspaces that will violate the upcoming policy change, allowing the administrator to give workspace owners a warning before merging the PR. The results of the previews are also pushed back to the VCS provider with checks for branch policies. These previews do not cause current runs to fail.
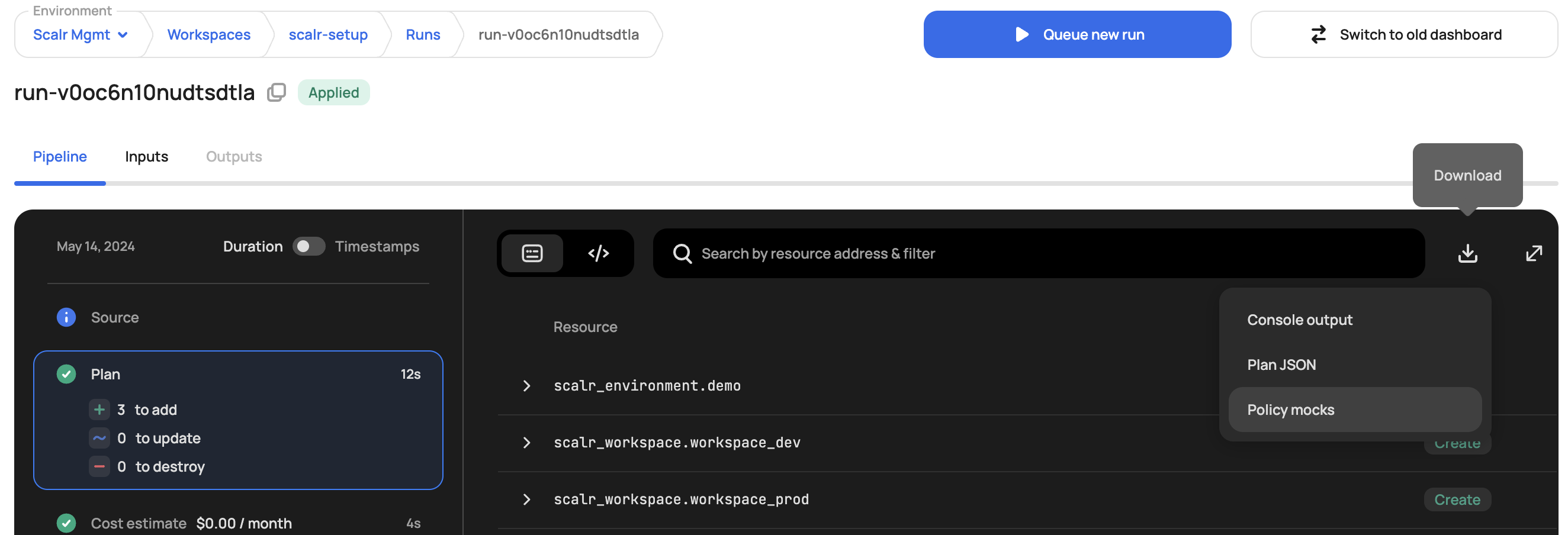
Policy Mocks
Policy mocks in Scalr are very helpful in creating OPA policies as they present all of the tfrun and tfplan information that is possible to use within an OPA policy. A policy mock can be downloaded per run in the individual run dashboard:
More Resources
For examples of OPA policies, please visit our GitHub repository: Open Policy Agent Examples
To learn more about using the terraform plan data with OPA please review our Scalr OPA Blog series, in particular OPA Series Part 3: How to analyze the JSON plan.
To learn more about writing OPA policies for Terraform and Scalr we recommend the following resources:
Video
More of a visual learner? Check out this feature on YouTube.
Updated 9 months ago